Podcast Summary
I’ve been listening to some podcasts lately and I thought it would be dope to have them summarized chatgpt-style after each episode. Unfortunately I wasn’t super convinced with the free solutions I’ve found online, either YouTube wasn’t supported out of the box or the summary was meh.
I don’t think it’s that hard to build so let’s try
Idea
- Use the YouTube API to get the transcript of the video (easier than using text to speech or the video itself and whatnot)
- Clean up the transcript (remove timestamps, speaker names and other artifacts)
- Chunkify the transcript into smaller parts
- Use chatGPT to summarize each chunk
- Collate the chunks into a final summary and voila
The whole script and an example output are available here : https://github.com/Cyril9227/YoutubeSummary
Getting the transcript
Fortunately, everything exists in python.
First some quick regex to extract the video_id from the YouTube URL:
import re
def get_video_id(youtube_url):
"""
Extract video ID from YouTube URL.
It handles patterns like youtube.com/watch?v=VIDEO_ID or youtu.be/VIDEO_ID
"""
patterns = [
r'(?:youtube\.com/watch\?v=|youtu\.be/)([A-Za-z0-9_-]+)',
r'youtube\.com/embed/([A-Za-z0-9_-]+)'
]
for pattern in patterns:
match = re.search(pattern, youtube_url)
if match:
return match.group(1)
raise ValueError("Invalid YouTube URL")
We can then extract the transcript like so :
# pip install youtube-transcript-api
def get_transcript(video_id):
"""
Get transcript from YouTube video.
By default, it always picks manually created transcripts over automatically created ones.
"""
try:
return YouTubeTranscriptApi.get_transcript(video_id)
except Exception as e:
raise Exception(f"Error fetching transcript: {str(e)}")
Cleanup 1
Transcripts, especially the automatically generated ones, can be quite messy. We’ll need to clean them up a bit, removing speaker labels, timestamps, and other artifacts.
Here’s a first (AI generated) pass at it:
def clean_transcript_text(transcript_list):
"""Clean and format transcript text with proper sentence breaks."""
def clean_fragment(text):
"""Clean individual text fragments."""
# Normalize Unicode characters
text = unicodedata.normalize('NFKD', text)
# Remove non-breaking spaces and similar artifacts
text = re.sub(r'\[\s*_+\s*\]', '', text) # Remove [___] patterns
text = re.sub(r'\xa0', ' ', text) # Replace non-breaking spaces
text = re.sub(r'\u200b', '', text) # Remove zero-width spaces
text = re.sub(r'\s+', ' ', text) # Normalize all whitespace
return text.strip()
# First pass: join text fragments into a single string
full_text = ""
for i, entry in enumerate(transcript_list):
current_text = clean_fragment(entry['text'])
# Skip empty entries
if not current_text:
continue
# Check if this fragment ends with sentence-ending punctuation
ends_with_punct = current_text[-1] in '.!?'
# Add the current text
full_text += current_text
# If this doesn't end with punctuation, check if we should add a space
if not ends_with_punct and i < len(transcript_list) - 1:
next_text = clean_fragment(transcript_list[i + 1]['text'])
# Add space if the next fragment doesn't start with punctuation
if next_text and not next_text[0] in '.,!?':
full_text += ' '
# Clean up common transcript issues
cleaned_text = (
full_text
# Remove multiple spaces
.replace(' ', ' ')
# Add space after period if missing
.replace('.','. ')
.replace('. ', '. ')
# Add space after comma if missing
.replace(',',', ')
.replace(', ', ', ')
# Remove spaces before punctuation
.replace(' .', '.')
.replace(' ,', ',')
.replace(' !', '!')
.replace(' ?', '?')
# Fix common transcript artifacts
.replace('[Music]', '')
.replace('[Applause]', '')
.replace('[Laughter]', '')
)
# Remove speaker labels and timestamps using regex
cleaned_text = re.sub(r'\[?Speaker \d+\]?:\s*', '', cleaned_text)
cleaned_text = re.sub(r'\[\d{2}:\d{2}:\d{2}\]', '', cleaned_text)
# Split into sentences and rejoin with proper spacing
sentences = re.split(r'(?<=[.!?])\s+', cleaned_text)
formatted_text = ' '.join(sentence.strip() for sentence in sentences if sentence.strip())
return formatted_text
Not a NLP expert, can surely be much more sophisticated but good enough for a rough clean up.
Chunkify and clean up 2
ChatGPT API has a limit of input tokens, so we’ll need to chunkify the transcript into smaller parts.
def chunk_text(text, max_tokens=4000):
"""Split text into chunks to respect token limits."""
words = text.split()
chunks = []
current_chunk = []
current_length = 0
for word in words:
# Approximate token count (words * 1.3 for safety margin)
word_tokens = len(word.split()) * 1.3
if current_length + word_tokens > max_tokens:
chunks.append(' '.join(current_chunk))
current_chunk = [word]
current_length = word_tokens
else:
current_chunk.append(word)
current_length += word_tokens
if current_chunk:
chunks.append(' '.join(current_chunk))
return chunks
For the actual cleaning of the chunks, I thought of actually using chatGPT itself to ensure that the input to the summary task is as clean as possible. It has some trade-off of course, we’re using one extra API call per chunk (cost + time) and we might also introduce hallucinations (although recent models are really good now) but we should be getting a much higher quality input for the model later on
# pip install openai
def cleanup_chunk(client, chunk):
"""Using the LLM to directly cleanup each chunk, much better results than regex/code based cleanup."""
try:
cleanup_response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "system",
"content": """You are an expert at cleaning up raw podcast transcripts. Your tasks:
1. Fix sentence structure and punctuation
2. Remove filler words (um, uh, like, you know etc.)
3. Clean up false starts and repeated phrases
4. Maintain the original meaning and speaker's intent
5. Keep important verbal emphasis or emotional context
6. Present the text as clean, properly punctuated paragraphs
Only return the cleaned text, no explanations or meta-commentary."""
},
{
"role": "user",
"content": f"Clean up this podcast transcript section, maintaining its meaning but removing speech artifacts:\n\n{chunk}"
}
],
temperature=0.3, # Lower temperature for more consistent cleaning
max_tokens=1500
)
cleaned_chunk = cleanup_response.choices[0].message.content
except Exception as e:
raise Exception(f"Couldn't clean up input chunk because of {e}")
return cleaned_chunk
This step might not even be necessary, I’d need to experiment…
Actual summary
Finally, each clean chunk can be summarized using chatGPT:
def summarize_chunk(client, cleaned_chunk, topic="finance, crypto"):
try:
summary_response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "system",
"content": f"""You are a skilled podcast summarizer and a {topic} expert :
1. Identify the main topics and key points
2. Capture important insights and arguments
3. Include relevant examples or cases mentioned
4. Maintain the logical flow of the discussion
5. Highlight any significant conclusions or takeaways
6. Ignore low stake exchanges such as background presentation of the guests etc."""
},
{
"role": "user",
"content": f"Provide a detailed summary of this podcast section:\n\n{cleaned_chunk}"
}
],
temperature=0.7,
max_tokens=500
)
except Exception as e:
raise Exception(f"Error generating summary: {str(e)}")
return summary_response.choices[0].message.content
Putting it all together
# Need to setup dev API from platform.openai.com/
client = OpenAI(api_key=API_KEY)
youtube_link = "https://youtu.be/SFTvhVGx_DU"
video_id = get_video_id(youtube_link)
transcript = get_transcript(video_id)
clean_transcript = clean_transcript_text(transcript)
chunks = chunk_text(clean_transcript)
chunk_summaries = []
for i, chunk in enumerate(chunks):
print(f"Processing chunk {i}/{len(chunks)}...")
chunk = cleanup_chunk(client, chunk)
summary = summarize_chunk(client, chunk)
chunk_summaries.append(summary)
# Usual chatgpt markdown format string
final_summary = "\n\n".join([
"# Podcast Summary",
"## Overview",
*chunk_summaries,
])
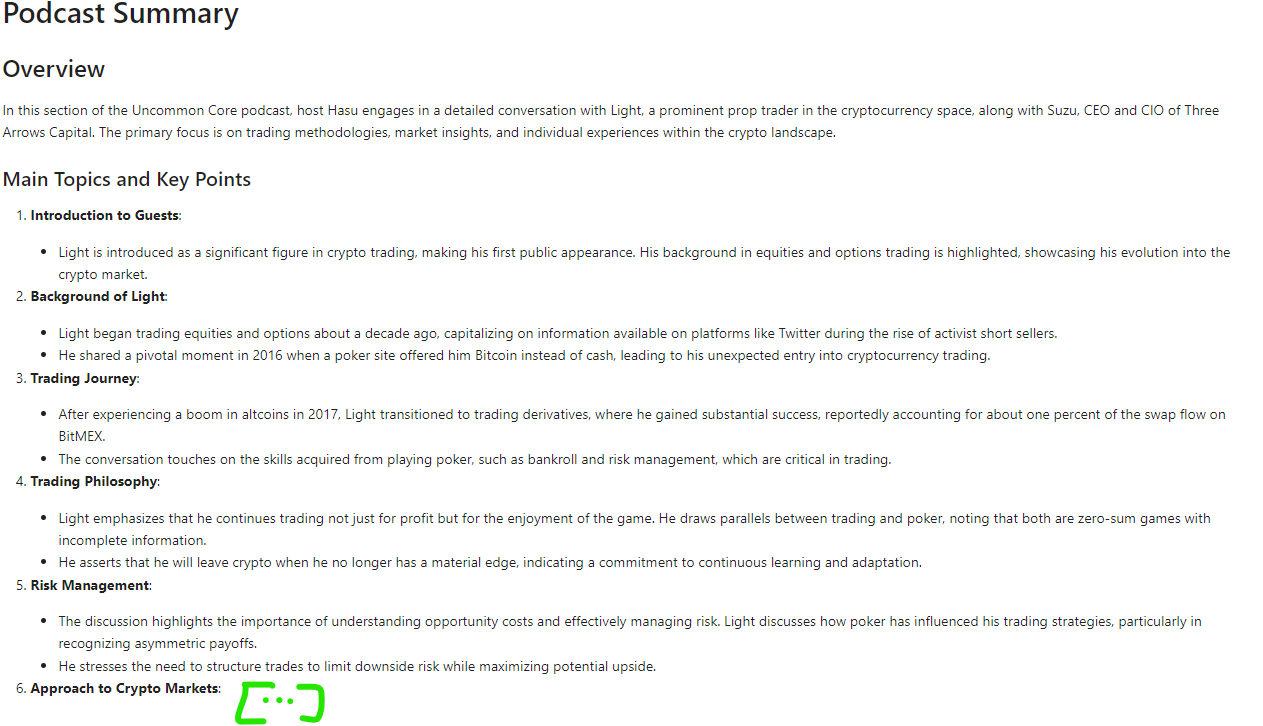
Result :
To do
- Test without chatgpt cleanup
- Handle rate limit error with breakoff lib or similar
- Build an app or web interface to use the script
- Push full code
- Play with the prompts to make summaries more concise + formatting