Soyjack Detector

Why ?
Because it’s funny
How ?
The whole thing is actually quite simple with Google Face Landmarker, which is basically 3 models packaged together:
- Face detection model: detects the presence of faces with a few key facial landmarks
- Face mesh model: adds a complete mapping of the face. The model outputs an estimate of 478 3-dimensional face landmarks.
- Blendshape prediction model: receives output from the face mesh model predicts 52 “blendshape” scores, which are coefficients representing different facial expressions.
We just run this on a video with a secret soyjack algorithm and voilà, we can detect soyjacks in real time (from your webcam !!!)
For extra spice, we can also add a hands detector which works exactly the same.
Code
Need to install mediapipe and download the packaged models:
pip install -q mediapipe
wget -O face_landmarker.task -q https://storage.googleapis.com/mediapipe-models/face_landmarker/face_landmarker/float16/1/face_landmarker.task
wget -O hand_landmarker.task -q https://storage.googleapis.com/mediapipe-models/hand_landmarker/hand_landmarker/float16/latest/hand_landmarker.task
Then we can define some helper function to nicely draw the detected landmarks and face mesh on the original image:
from mediapipe import solutions
from mediapipe.framework.formats import landmark_pb2
def landmarks_to_proto(landmarks):
"""Convert landmarks to protocol buffer format."""
proto = landmark_pb2.NormalizedLandmarkList()
proto.landmark.extend([
landmark_pb2.NormalizedLandmark(x=landmark.x, y=landmark.y, z=landmark.z)
for landmark in landmarks
])
return proto
def draw_landmarks_with_style(image, landmark_list, connections, landmark_style=None, connection_style=None):
"""Draw landmarks with specified styles."""
solutions.drawing_utils.draw_landmarks(
image=image,
landmark_list=landmark_list,
connections=connections,
landmark_drawing_spec=landmark_style,
connection_drawing_spec=connection_style
)
def draw_face_landmarks_on_image(rgb_image, detection_result):
"""Draw face landmarks, mesh, contours, and irises on the image."""
face_landmarks_list = detection_result.face_landmarks
annotated_image = np.copy(rgb_image)
for face_landmarks in face_landmarks_list:
face_proto = landmarks_to_proto(face_landmarks)
# Define face mesh drawing configurations
mesh_styles = [
(solutions.face_mesh.FACEMESH_TESSELATION,
solutions.drawing_styles.get_default_face_mesh_tesselation_style()),
(solutions.face_mesh.FACEMESH_CONTOURS,
solutions.drawing_styles.get_default_face_mesh_contours_style()),
(solutions.face_mesh.FACEMESH_IRISES,
solutions.drawing_styles.get_default_face_mesh_iris_connections_style())
]
# Draw all face mesh components
for connections, style in mesh_styles:
draw_landmarks_with_style(
annotated_image,
face_proto,
connections,
connection_style=style
)
return annotated_image
def draw_hands_landmarks_on_image(rgb_image, detection_result):
"""Draw hand landmarks and connections on the image."""
hand_landmarks_list = detection_result.hand_landmarks
annotated_image = np.copy(rgb_image)
for hand_landmarks in hand_landmarks_list:
hand_proto = landmarks_to_proto(hand_landmarks)
draw_landmarks_with_style(
annotated_image,
hand_proto,
solutions.hands.HAND_CONNECTIONS,
landmark_style=solutions.drawing_styles.get_default_hand_landmarks_style(),
connection_style=solutions.drawing_styles.get_default_hand_connections_style()
)
return annotated_image
The actual inference models can simply be created from the downloaded model like so :
from mediapipe.tasks import python
from mediapipe.tasks.python import vision
# FACE DETECTION
base_options = python.BaseOptions(model_asset_path='face_landmarker.task')
options = vision.FaceLandmarkerOptions(base_options=base_options,
output_face_blendshapes=True, # Needed to get facial expressions scores
output_facial_transformation_matrixes=False,
num_faces=1)
detector_face = vision.FaceLandmarker.create_from_options(options)
# HANDS DETECTION
base_options = python.BaseOptions(model_asset_path='hand_landmarker.task')
options = vision.HandLandmarkerOptions(base_options=base_options,
num_hands=2)
detector_hand = vision.HandLandmarker.create_from_options(options)
We need to define a few more helper functions for the webcam stuff and text overlay:
import cv2
def setup_webcam(camera_id=0, width=800, height=800):
"""
Initialize the webcam with specified parameters
"""
cap = cv2.VideoCapture(camera_id)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, height)
if not cap.isOpened():
raise IOError("Cannot open webcam")
return cap
def add_text_to_frame(frame, text, position=None):
height, width = frame.shape[:2]
if position is None:
position = (width - 500, 30)
font = cv2.FONT_HERSHEY_SIMPLEX
font_scale = 0.7
font_color = (255,192,203)
thickness = 2
(text_width, text_height), baseline = cv2.getTextSize(text, font, font_scale, thickness)
cv2.rectangle(frame,
(position[0] - 5, position[1] - text_height - 5),
(position[0] + text_width + 5, position[1] + 5),
(0, 0, 0),
-1)
cv2.putText(frame,
text,
position,
font,
font_scale,
font_color,
thickness)
return frame
The main loop is quite simple (press Q to exit), we just ingest frames from the webcam feed and run the models on each frame :
import mediapipe as mp
def main(privacy=False):
cap = setup_webcam()
try:
while True:
# Read frame from webcam
ret, frame = cap.read()
if not ret:
print("Failed to grab frame")
break
# Convert the webcam frame into correct format and run inference
rgb_image = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
mp_image = mp.Image(mp.ImageFormat.SRGB, data=rgb_image)
detection_result_face = detector_face.detect(mp_image)
detection_result_hands = detector_hand.detect(mp_image)
# If turned on, only display the detected face landmarks
if privacy:
frame = np.zeros(frame.shape)
# Draw detected landmarks on the webcam frame
annotated_image = draw_face_landmarks_on_image(frame, detection_result_face)
annotated_image = draw_hands_landmarks_on_image(annotated_image, detection_result_hands)
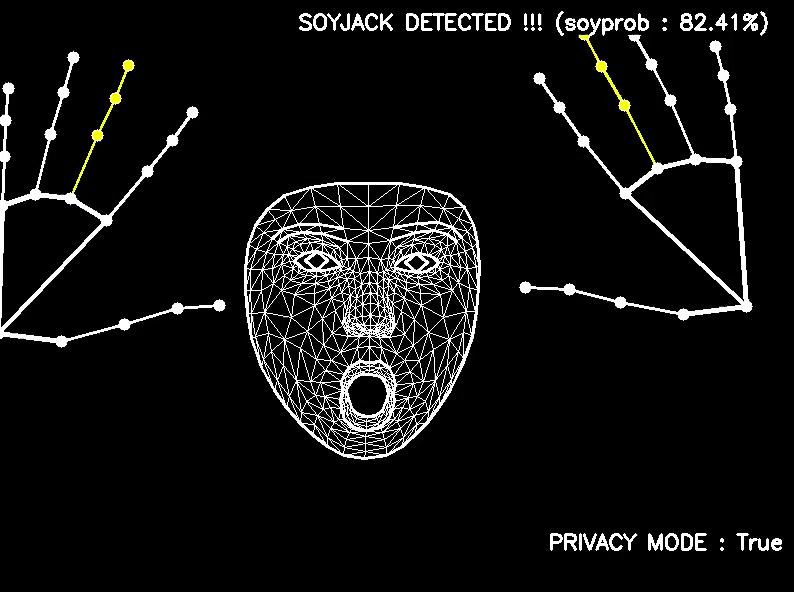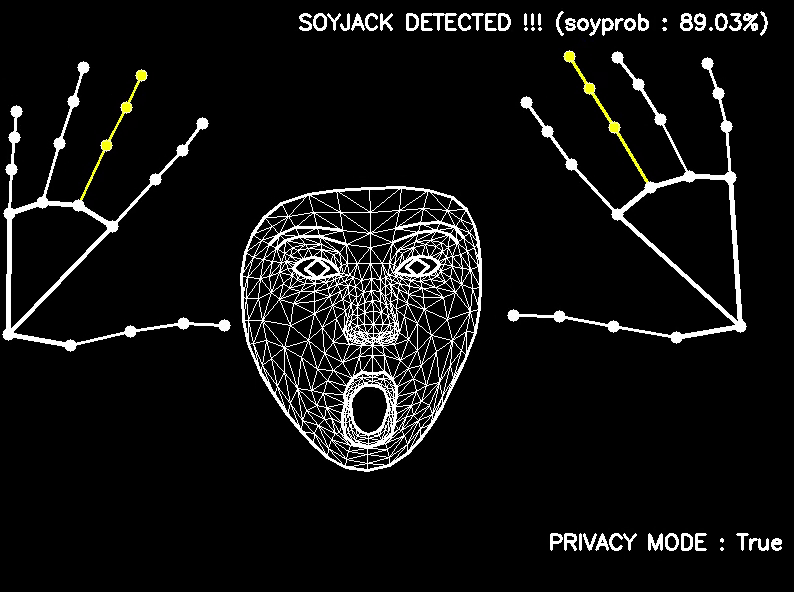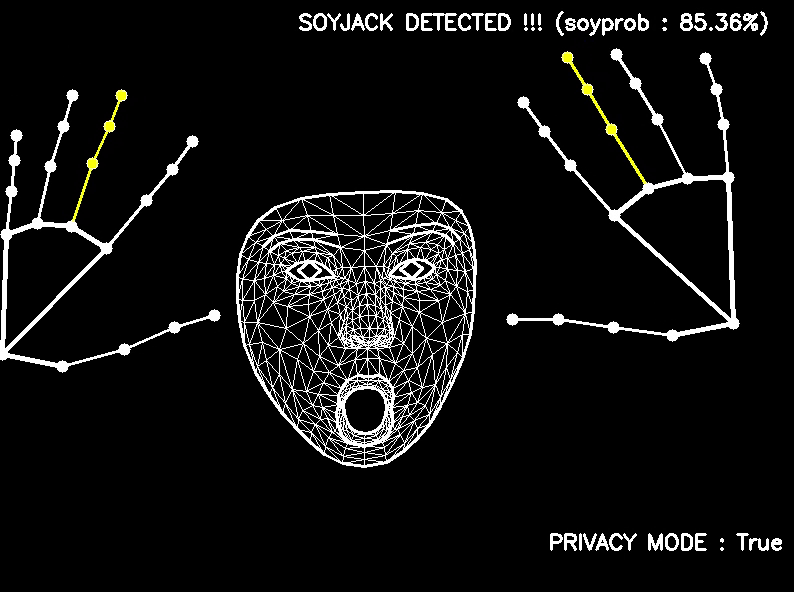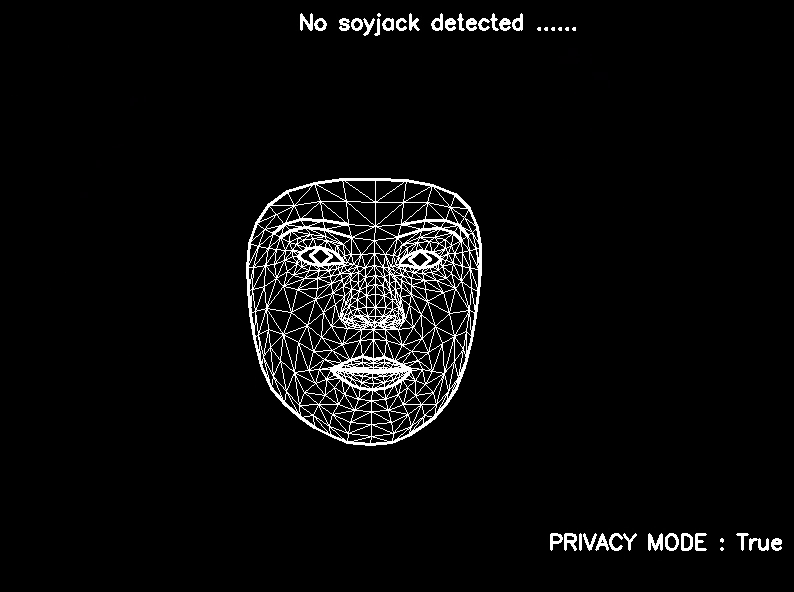
# Top secret algorithm to detect a soyface based on the model outputs
text = "No soyjack detected ......"
jaw_open = 0
eyes_wide = 0
brows_up = 0
smile_wide = 0
try:
for d in detection_result_face.face_blendshapes[0]:
if d.category_name == 'jawOpen':
jaw_open = d.score
elif d.category_name in ['eyeWideLeft', 'eyeWideRight']:
eyes_wide = max(eyes_wide, d.score)
elif d.category_name in ['browOuterUpLeft', 'browOuterUpRight']:
brows_up = max(brows_up, d.score)
elif d.category_name in ['mouthSmileLeft', 'mouthSmileRight']:
smile_wide = max(smile_wide, d.score)
# Top secret
soyjack_score = (eyes_wide * 0.3 + brows_up * 0.4 + smile_wide * 0.3)
if jaw_open >= 0.5 or soyjack_score >= 0.5:
soyjack_score = max(jaw_open, soyjack_score)
text = f"SOYJACK DETECTED !!! (soyprob : {soyjack_score:.2%})"
# Display the soyscore if detected
annotated_image = add_text_to_frame(annotated_image, text)
annotated_image = add_text_to_frame(annotated_image, f"PRIVACY MODE : {privacy}", position=(annotated_image.shape[1] - 250,
annotated_image.shape[0] - 50))
cv2.imshow('Webcam Feed', annotated_image)
# Might fail in case of extreme occlusion etc, just ignore the frame
except Exception as e:
print(f"NO LANDMARKS DETECTED : {e}")
# Break the loop when 'q' is pressed
if cv2.waitKey(1) & 0xFF == ord('q'):
break
finally:
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
main(privacy=False)
That’s pretty much it. If I’m not lazy I’ll package it into an app and add a simple frontend and maybe more options.
Happy soyjacking !!!